ASA_PT_Spring_Symposium_2019.pptx
May, 2017
- ASA Prinecton-Trenton Chapter Spring 2017 Symposium
Dear Colleagues,
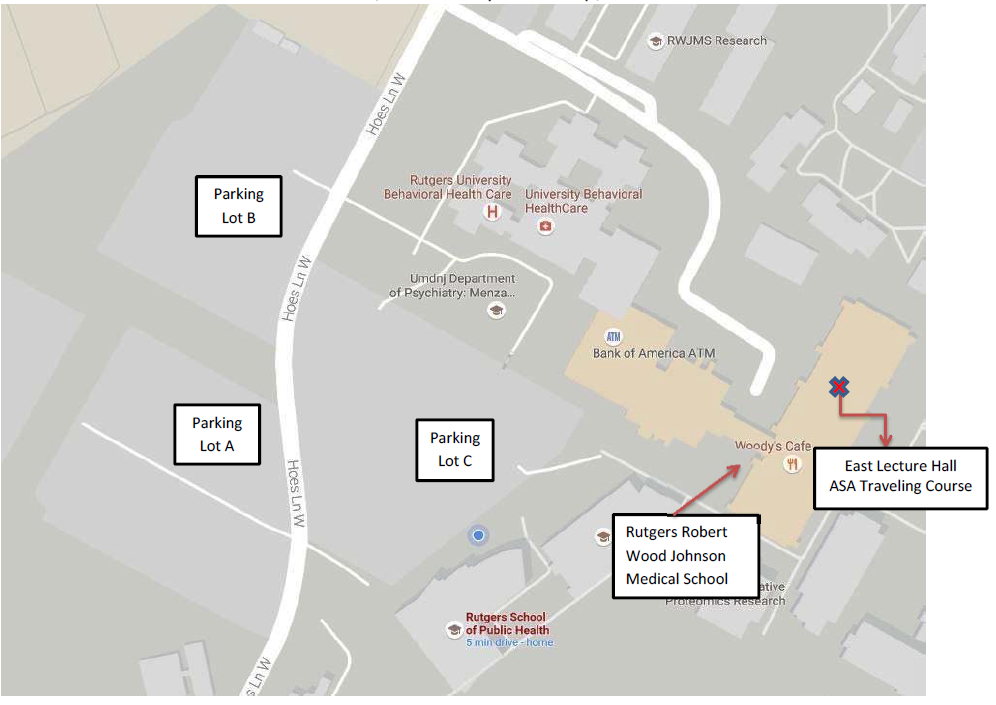
The ASA Princeton-Trenton Chapter in New Jersey is organizing a Spring Statistics Symposium from 9:00 AM to 2:30 PM EDT on Friday, May 5, 2017 in the East Lecture Hall, Rutgers Robert Wood Johnson Medical School.
The focus of the Spring Symposium is on New Advancement in Biomarkers/Precision Medicine/Enrichment Design. It aims to introduce participants to the new advancement of statistical methods and applications in precision medicine, to discuss the challenges and solutions related to the use of biomarkers in design and analyses for clinical trials and translational research, and to review present knowledge on biomarkers.
Tentative agenda:
|
Time
|
Topic
|
Speaker
|
|
8:30 - 9:00 AM
|
Registration
|
|
|
9:00 - 9:05 AM
|
Greetings and Introduction
|
|
|
9:05 - 9:50 AM
|
The Reality of Personalized Oncology – 2017
Slides
|
Richard Simon,Associate Director, Division of Cancer Treatment & Diagnosis, Biometric Research Program
Chief, Computational & Systems Biology Branch, National Cancer Institute
|
|
9:50 - 10:35 AM
|
Statistical Challenges in Precision Medicine with a Focus on Companion Diagnostics
Slides
|
Gregory Campbell,President, GCStat Consulting, LLC. Former Director, Division of Biostatistics, CDRH/FDA
|
|
10:35 - 10:50 AM
|
Break
|
|
|
10:50 - 11:35 AM
|
Two Novel Designs for Small Populations: The Confirmatory Basket Trial and the Informational Design
Slides
|
Robert A. Beckman, MD,Professor of Oncology and of Biostatistics, Bioinformatics, and Biomathematics,Georgetown University Medical Center
|
|
11:35 - 12:20 PM
|
Developing an Immunohistochemistry Test for Programmed Cell Death Ligand 1 (PD-L1) as a Companion Diagnostic for Pembrolizumab
|
Deepti Auroa-Garg,Director, Biomarker and Diagnostics Leader, Merck Oncology
|
|
12:20 - 1:30 PM
|
Lunch Break
|
|
|
1:30 - 2:30 PM
|
Panel discussion
|
Richard Simon, Greg Campbell,
Robert A. Beckman,Deepti Auroa-Garg
|
A light breakfast and lunch buffet are provided with registration. The parking lots [Parking Lot A, B, and C] are conveniently located near the event location, and will have Signs indicating event parking. For your information, a parking map is attached.
ABSTRACT:
1. Richard Simon: The Reality of Personalized Oncology– 2017
Oncology is a set of diseases thought to result in large part from the development of genomic mutations and other DNA alterations. The development of inexpensive DNA sequencing has enabled the development of new cancer classifications based on the presence or absence of genomic alterations. This classification has been strongly correlated with response to molecularly targeted treatment and this has had a profound influence on pharmaceutical drug development strategies. These strategies have led to changes in clinical development plans as the old “aspirin paradigm” is no longer appropriate as a basis for clinical trial design in many cases.
In my talk I will describe some successes in accommodating clinical trial design to developments in cancer biology. I will also describe some remaining challenges such as utilization of quantitative biomarkers, prospective-retrospective studies and designs which adaptively identify the intended use population.
2. Gregory Campbell: Statistical Challenges in Precision Medicine with a Focus on Companion Diagnostics
Since the successful sequencing of the human genome early this century, the public has begun to see practical breakthroughs through advancements in precision medicine; namely, therapeutic medical products tailored to the patient using a biomarker. With the recent genetic and genomic advancements, there has been an explosion in the amount of biomarker data. One statistical challenge is that of co-development: how to confirm that a particular therapeutic product is safer or more efficacious for an individual based on the particular result of a companion diagnostic (usually genomic) test. Various types of diagnostic tests or biomarkers are introduced and illustrated. Another statistical challenge is that of design: how can diagnostic tests and therapeutic products be co-developed, especially if the drug clinical trial precedes the development of a market ready diagnostic test to be used in concert with the drug. Statistical designs that allow for adaptation or for the use of retrospective data in a scientifically valid manner are discussed. Analysis of data from such trials is also challenging, particularly of multiplicity, selection of a cutoff for the test, and missing data. Several drug-diagnostic examples are reviewed and a number of clinical trials are discussed. The implications for the future of individualized medicine are enormous. An interdisciplinary effort involving.
3. Robert Beckman: Two Novel Designs for Small Populations: The Confirmatory Basket Trial and the Informational Design
Two novel designs will be presented, the confirmatory basket trial and the informational design.
Increasingly, tumors are defined on a molecular basis rather than only on histology, and targeted agents which address these molecular subtypes are being approved. This profusion of molecular subtypes creates “rare” diseases as subsets of common cancers, leading to difficulties in enrolling sufficiently large cohorts for confirmatory trials. However, if the molecular subtype is shared across various histologies, these may be pooled into a basket trial. To date, basket trials have been primarily for exploratory early development. We present a new confirmatory basket trial design which will provide patients in niche indications with enhanced access to novel therapies, facilitate development and full approval for niche indications, allow accelerated approval for indications within a basket based on a surrogate endpoint, reduce development cost by combining trials into one, and enhance the ability of regulatory authorities to evaluate risk and benefit in niche indications.
The informational design allows adaptation when the ability of interim endpoints to predict final definitive endpoints is uncertain. A fraction of the patients are designated as an informational cohort and their data governs an adaptation at the end of the study. These patients are also used in the final analysis with suitable alpha adjustment. Applications include alpha allocation between a full population and a subset, setting a threshold for a continuous biomarker, and a speculative application of a confirmatory trial which selects its own primary endpoint. The latter may be useful for rare diseases where the natural history is unknown and difficult to obtain.
4. Deepti Auroa-Garg: Developing an Immunohistochemistry Test for Programmed Cell Death Ligand 1 (PD-L1) as a Companion Diagnostic for Pembrolizumab
Keytruda® (Pembrolizumab) an anti-PDL1 therapy has been approved in first and second line Non-Small Cell Lung Cancer (NSCLC). This approval is restricted to patients whose tumors express PDL1 ≥ 50% for first line and ≥ 1% for second line thereby heralding a new era in immune-oncology and personalized medicine. The talk will focus on the development of a PDL1 IHC diagnostic test for Keytruda eligibility and cover aspects of selection of scoring guidelines in training sets and their application in Phase III trials.
Regards,
ASA Princeton-Trenton Chapter